Azure Data Factory – Concurrency
Heute geht es um das Thema „Concurrency“ in der Azure Data Factory.
Und das passt wunderbar zu unserem letzten Beitrag, der von der automatischen Verarbeitung neu angelieferter Files im Azure Blob Storage handelte. In diesem Beitrag hatten wir auf einen kleinen Stolperstein bei der Verwendung von Event-Triggern in der Azure Data Factory hingewiesen, auf den in den Microsoft-Dokumentationen hingewiesen wird und der auch unbedingt beherzigt werden sollte.
Dabei versprachen wir, einen weiteren Punkt anzusprechen, der wiederum tief in der Dokumentation versteckt ist, aber dummerweise nicht übersehen werden darf. Wie in dem oben erwähnten Beitrag beschrieben, hatten wir die Concurrency der Pipeline auf 10 gestellt und dachten, parallele Verarbeitung in der Cloud wäre doch eine gute Idee…
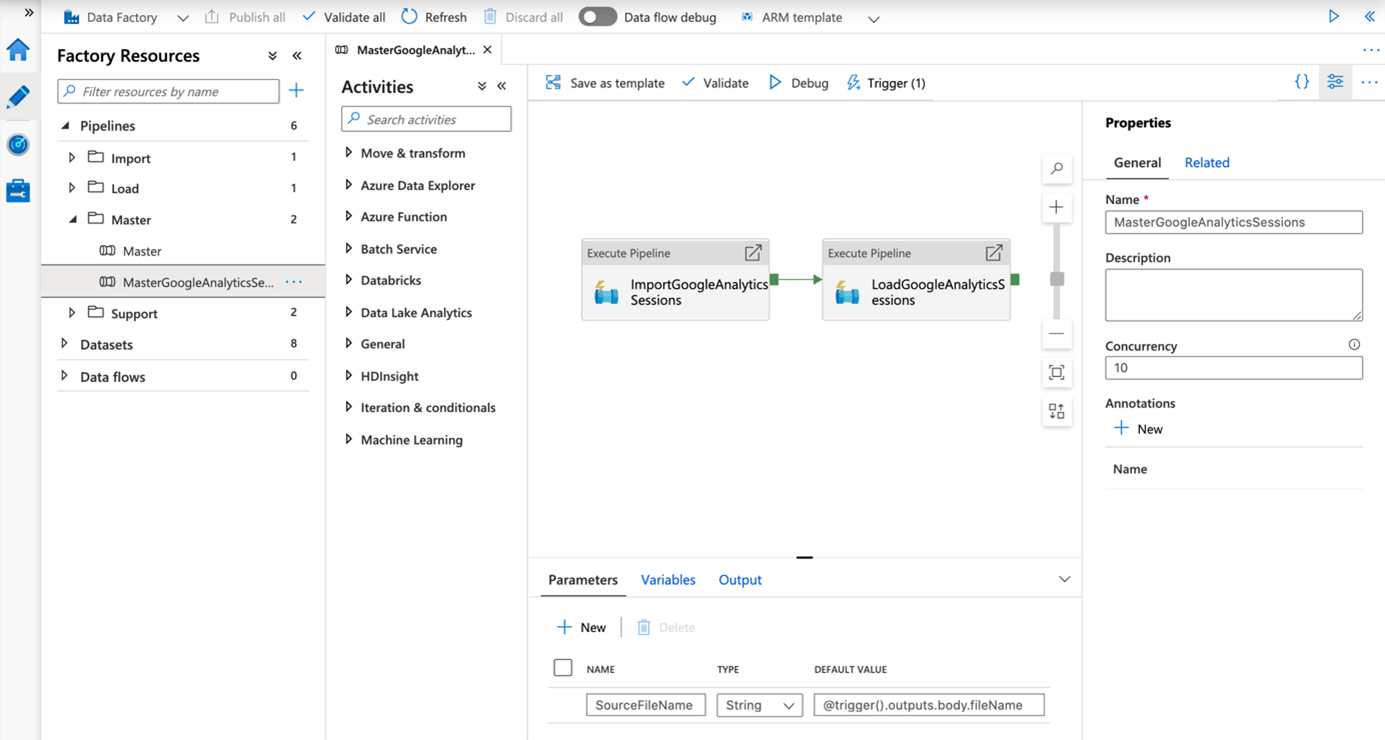
…aber dummerweise trafen gleichzeitig mehr als 100 Files ein.
Und damit feuerte unser Trigger (erfolgreich!) über 100 Mal und wurde entsprechend gequeued.
Und dann passierte das:
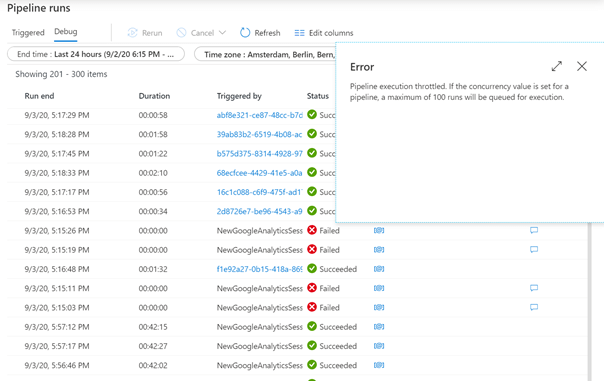
Warum dieser Fehler auftritt, steht hier: https://docs.microsoft.com/en-us/azure/azure-resource-manager/management/azure-subscription-service-limits#data-factory-limits
Auszug der Seite:
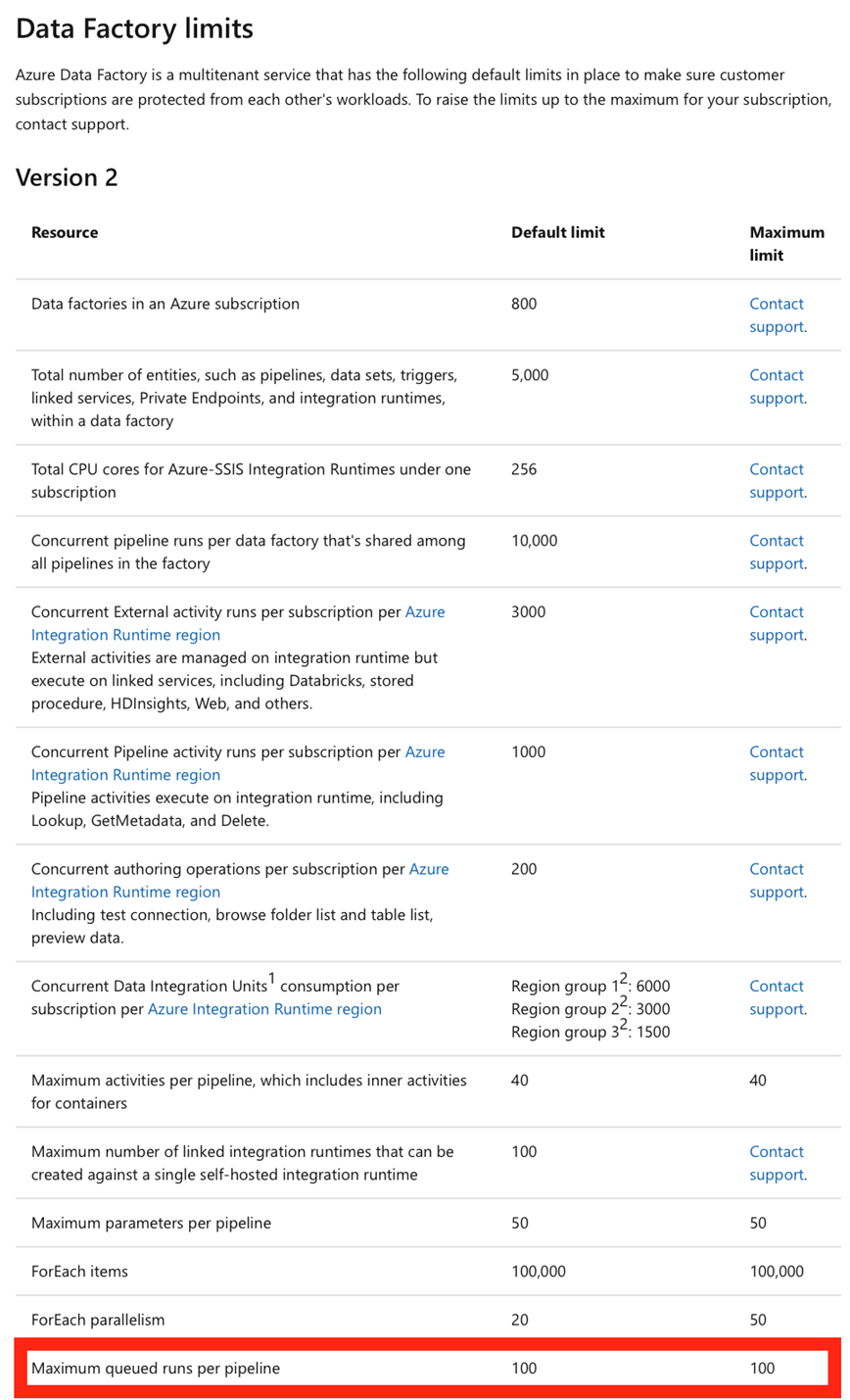
Und tatsächlich, wenn der Default-Wert von 1 für die Concurrency der Pipeline eingestellt bleibt, tritt der Fehler nicht auf, der ganze Prozess läuft dann wie gewünscht.
Naja, nicht ganz wie gewünscht – er läuft dann halt sequenziell und das dauert daher … laaange.
Wir wollen also tausende von Files einlesen und können das nur sequenziell.
Vielleicht hat ja Microsoft ein Einsehen und hebt dieses Limit (stark) an.
Vielleicht schon, wenn Sie das hier lesen – also probieren Sie es ruhig mal aus!