Azure Data Factory – Event Grid, Trigger und parallele Verarbeitung
Wir sind eine alteingesessene „Microsoft-Company“.
Seit Jahrzehnten bauen wir unsere ETL-Strecken mit den bewährten Bordmitteln, allen voran mit den SQL Server Integration Services (SSIS). Doch die Welt dreht sich weiter und die IT-Welt rotiert sogar mit Überschallgeschwindigkeit. Aus dem einstigen Hype-Thema „Cloud“ ist mittlerweile eine gestandene Industrie geworden.
Als mehrfacher Microsoft Gold Partner haben wir dieses Thema schon früh auf unserer internen Prioritätenliste ganz nach oben gesetzt.
Dabei entdecken wir ständig etwas Neues. Die Microsoft Cloud Technologie entwickelt sich so rasant weiter, dass wir kaum hinterherkommen, alle neuen Features und Möglichkeiten in unseren Projekten zeitnah einzusetzen – und manchmal finden wir auch seltsames.
Kürzlich hatten wir im Rahmen eines Kundenprojektes ein typisches Problem:
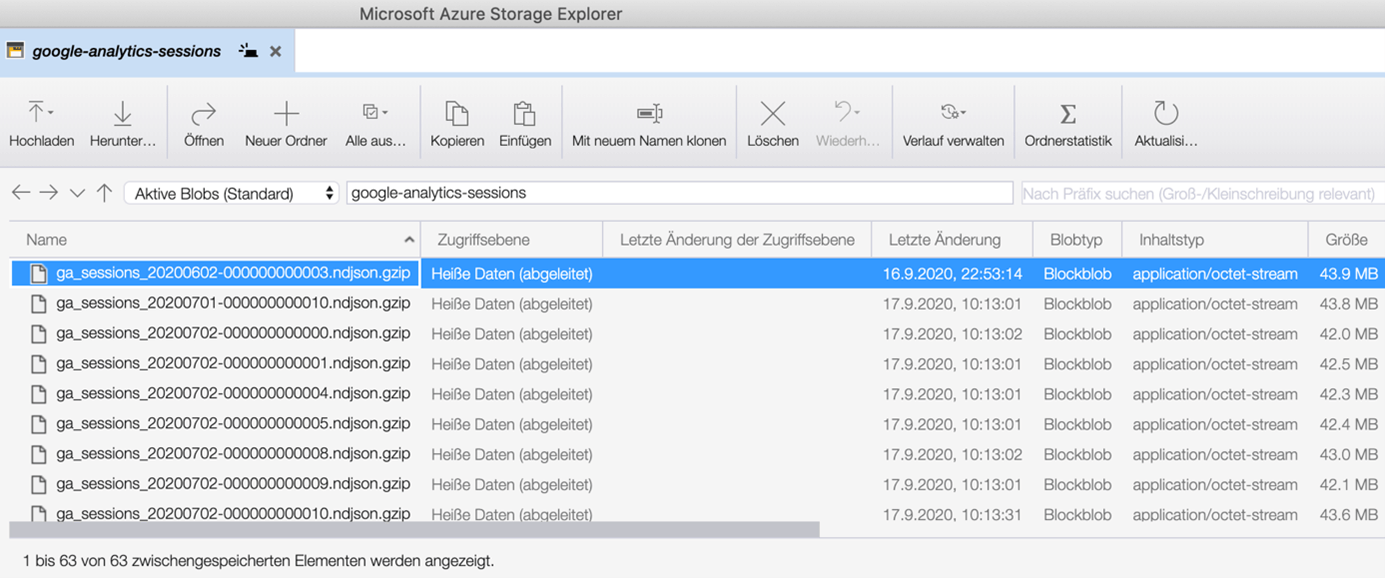
Von irgendwo aus der großen weiten Cloud tropften regelmäßig JSON-Dateien in einen Azure Blob Storage Container. Diese Files sollen automatisch in eine Azure SQL Server Datenbank geladen werden und von da ihren Weg durch die ETL-Mühlen (per Azure Data Factory) bis in einen Power BI Bericht finden.
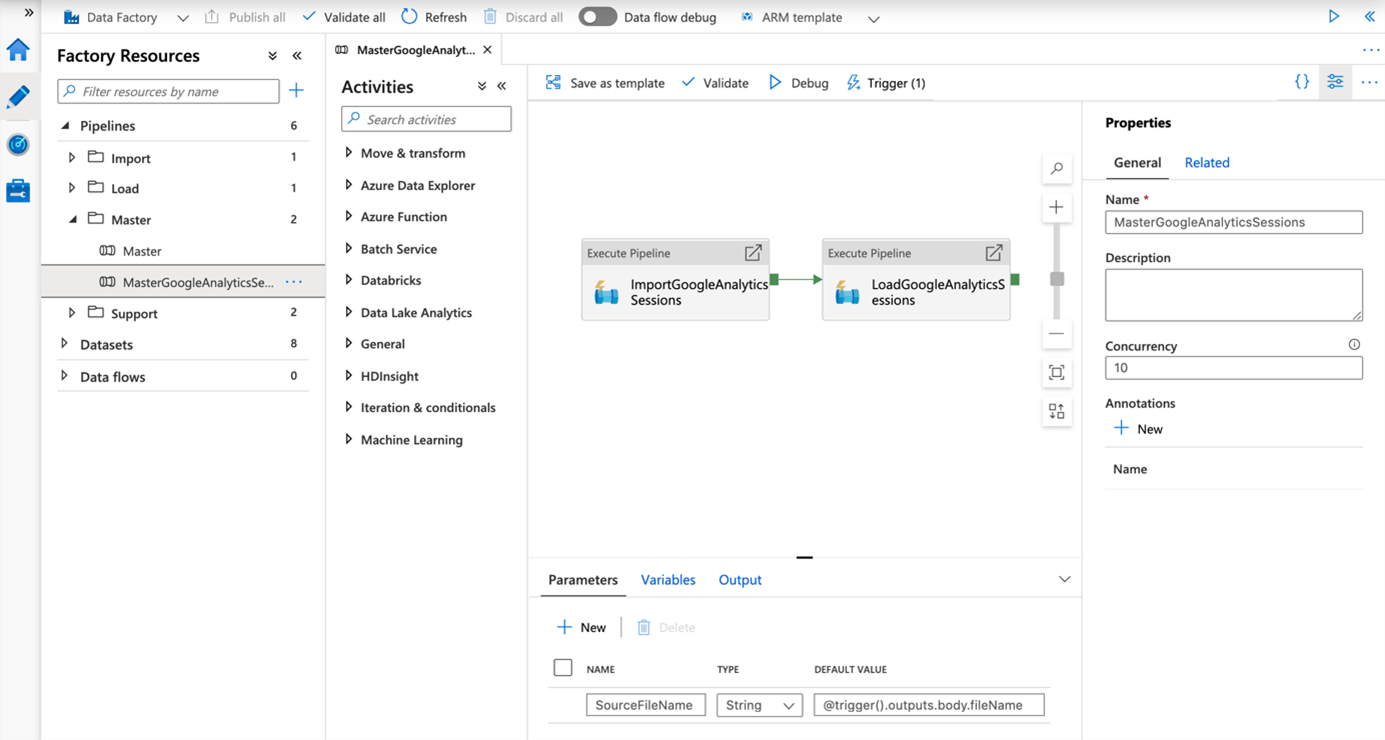
Der ganze Prozess findet ausschließlich in der Cloud statt – nichts mehr mit der guten alten on-premise Technologie! Und all das kann sogar noch skaliert werden. In der obigen Abbildung haben wir die Concurrency der Pipeline auf 10 gestellt, d.h. bis zu 10 Instanzen der Pipeline können parallel laufen, wenn in kurzer Zeit eine größere Anzahl Files eintrifft.
In der alten Welt hätten wir in klassischen SSIS-Paketen mit for-each-loop Containern die Files irgendwie gelesen und weiterverarbeitet. Für dieses alltägliche Problem bietet Microsoft in der Cloud eine elegante Lösung:
Die Azure Cloud reagiert einfach selbst auf das Eintreffen von neuen Files!
Dazu wird ganz einfach ein Trigger definiert, der auf das Eintreten eines „Blob created“ Events wartet und eine entsprechende Azure Data Factory Pipeline startet, die dann das frisch eingetroffene File weiterverarbeitet.
Wenn der Trigger gestartet ist sollte also folgendes passieren:
Ein File trifft ein – der Trigger feuert – die Pipeline wird „gequeued“, gelangt dann in irgendwann in den Status „In progress“ und schlussendlich (hoffentlich) in den Status „Succeeded“.
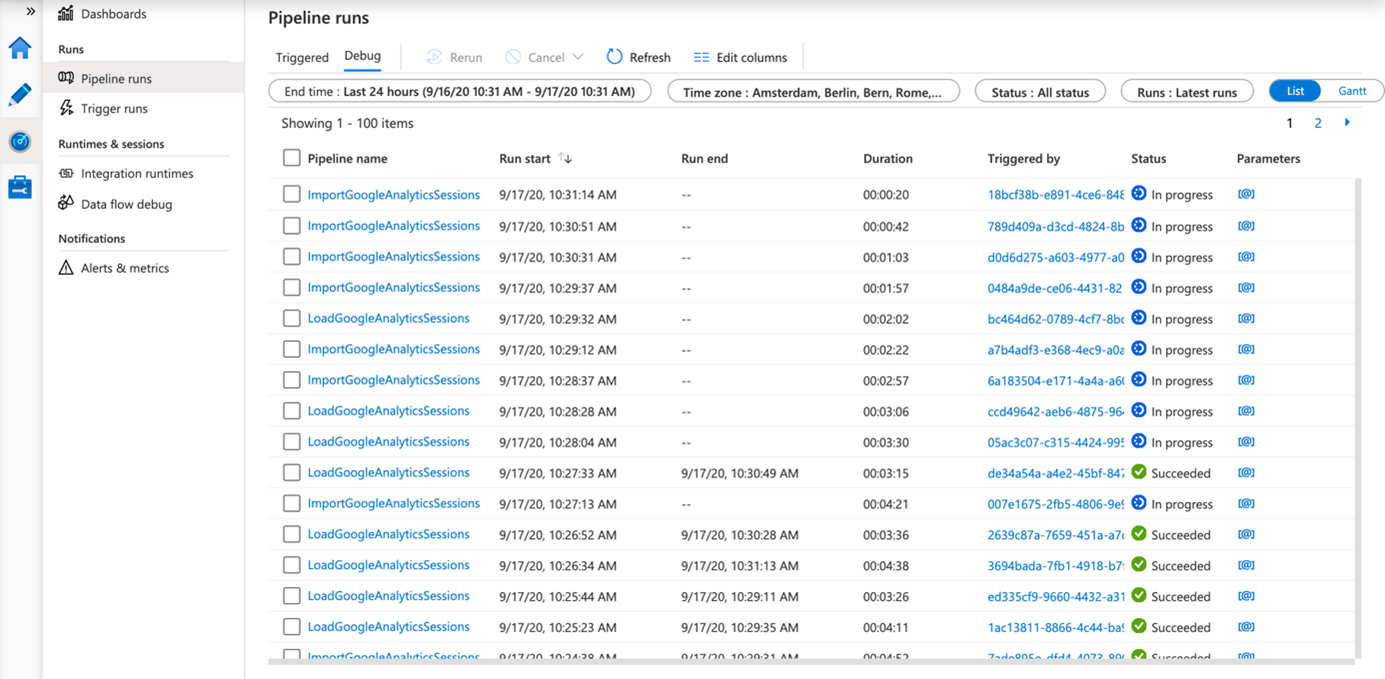
Der Trigger feuert jedes Mal, wenn ein neues File eintrifft und schiebt damit jedes Mal eine weitere Instanz der Pipeline in die Queue. Theoretisch können auf diese Weise automatisch viele (fast) gleichzeitig eintreffende Files (bei Bedarf auch) parallel verarbeitet werden.
Beim Lesen der entsprechenden Microsoft Dokumentation https://docs.microsoft.com/de-de/azure/data-factory/how-to-create-event-trigger findet sich folgender deutlich hervorgehobener Hinweis:

Und wie das gemacht wird, hat Microsoft auch gleich noch ausführlich beschrieben:
Da wir über alle Eventualitäten Bescheid wissen wollen, fragten wir uns:
„Der Hinweis ist so exponiert, was passiert eigentlich, wenn man ihn ignoriert?“
Die Antwort ist:
Gar nichts!
Die Files laufen alle nacheinander in den Blob Storage, es werden immer mehr und sonst – NIX. Keine Fehlermeldung, kein gut gemeinter Hinweis (außer dem oben erwähnten deutlich hervorgehoben in der Dokumentation). Hat man dann wie gefordert das Microsoft.EventGrid registriert, bleibt der Trigger trotzdem für alle Ewigkeit inaktiv.
Um letzten Endes doch noch das gewünschte Ziel zu erreichen, muss man einen neuen Trigger für die Pipeline erstellen und starten – und schließlich wird tatsächlich auf neu hinzukommende Files reagiert und die Pipeline automatisch gestartet!
Gut, das war ein Versuch aus reiner Neugier, alles reagiert „as designed“. Es wäre nur schön, beim Anlegen eines Event-Triggers einen kleinen Tipp zu bekommen, dass ein entsprechender Ressourcenanbieter registriert sein muss – denn wer liest schon Dokumentationen.
Aber, ein Problem hat das Ganze doch noch, aber das ist ein Thema für einen neuen Blogbeitrag!