Data Manipulation mit dplyr und Rstudio
Es ist später Nachmittag. Ich sitze nichtsahnend im Büro, da ertönt hinter mir eine fragende Stimme: „Kannst Du mir mal mit den Mathe-Hausaufgaben helfen?“. Es ist meine Tochter und sie hat mir eine Kopfnuss ganz nach meinem Geschmack mitgebracht.
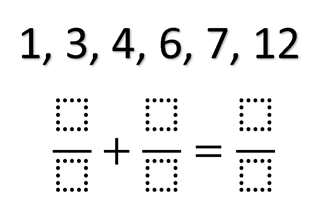
Die Aufgabe ist es, die oben abgebildeten Zahlen so in die Gleichung einzuordnen, dass die Rechnung stimmt.
Wir beginnen mit Raten, merken aber schnell, dass das gar nicht so einfach ist bei mehreren hundert möglichen Kombinationen. Als nächstes beginnen wir, anhand von Heuristiken die Möglichkeiten etwas einzugrenzen. Schnell fällt uns beispielsweise auf, dass die 12 nicht auf der rechten Seite stehen kann. Das hilft zwar etwas, aber der Groschen will bei uns beiden trotzdem einfach nicht fallen. Da bei mir ein wichtiges Meeting demnächst beginnt, ich meine Tochter aber nicht im Regen stehen lassen will, breche ich ausnahmsweise eines meiner eisernen Gesetze: Ich sage ihr die Lösung vor!
Wie? Durch eine sogenannte Brute Force Attack mittels des Computers und meiner liebsten Statistiksprache R.
Zuerst erstellen wir einen Vektor mit den Daten in RStudio und laden uns einige hilfreiche Pakete:
# load packages
require(tools);
require(dplyr);
# load possible numbers
Zahlenkarten <- c(1,3,4,6,7,12)
Das Paket gtools nutzen wir, da es eine Funktion für die Erzeugung von Permutationen enthält. So müssen wir das nicht selbst implementieren und sparen uns so viel Zeit. Das zweite Paket dplyr benötigen wir später und sollte bei jedem Data Scientist im Handwerkskoffer liegen, denn damit kann ich Dataframes auf sehr einfache Art und Weise manipulieren.
Nun erstellen wir unsere Permutationen. Durch gtools geht das in einem Einzeiler, wobei die Parameter n und r angeben, wie viele der Elemente aus unserem Vektor gezogen werden sollen. Da wir alle Elemente benötigen, nutzen wir die length Funktion, um das dynamisch zu übergeben.
# create all possible permutations
perms <- permutations(n = length(Zahlenkarten), r = length(Zahlenkarten), v = Zahlenkarten)
Das Ergebnis sieht sinnvoll aus und wir erhalten 720 verschiedene Möglichkeiten zur Anordnung.
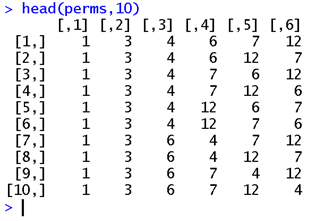
# convert to dataframe
perms.df <- as.data.frame(perms)
Am Ende müssen wir nur noch checken, welche der Zeilen unsere Gleichung erfüllt. Dies können wir mittels dply Paket ebenfalls sehr effizient lösen. V1-6 sind hierbei die vom Dataframe vergebenen Spaltennamen.
# check all rows, if they fulfill requirement
results <- perms.df %>%
mutate(isPossible = (V1/V2) + (V3/V4) == (V5/V6)) %>%
filter(isPossible)
Hierbei wird direkt die Macht von dplyr erkennbar, denn durch den sog. Pipe Operator (%<%) kann ich, ähnlich wie in PowerShell, mehrere aufeinander basierende Operationen hintereinander schachteln. Durch die vom Paket bereitgestellten Befehle kann man Dataframes ähnlich wie mit SQL als Menge betrachten und manipulieren. Die wichtigsten Methoden sind
- mutate() erstellt neue Spalten basierend auf existierenden Spalten einer oder mehrerer Zeilen
- select() selektiert Spalten aufgrund von Namen, Patterns oder Indexes
- filter() Filtert Zeilen auf basis von Constraints (Analog zum SQL WHERE)
- summarise() aggregiert mehrere Zeilen zu einer mithilfe einer Aggragtfunktion (z.B. SUM(), COUNT(), etc..)
- arrange() ändert die Reihenfolge der Zeilen (analog zum SQL ORDER BY)
- group_by() gruppiert mehrere Zeilen zu Buckets, auf die dann Aggregate angewandt werden können (analog zum SQL GROUP BY)
Dies ist der Grund, weshalb dplyr so beliebt bei Data Scientists ist: Man kann damit auf sehr einfache und konsistente Art und Weise Features für seine Machine Learning Projekte erstellen, was es zu einem vielseitigen Data Preparation Tool macht.
Was ist das Ergebnis unserer Rechnung?

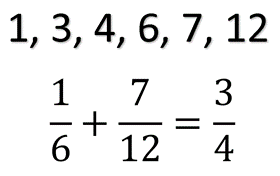
Das alles innerhalb von 5 Minuten gelöst und damit deutlich schneller als zu Fuß oder analytisch. Dieses Ergebnis zeigt auch eindrucksvoll, wie wichtig es ist ausreichend komplexe Kryptographie zu nutzen in unserer heutigen Zeit. Allzu einfach gewählte Passworter können durch Brute Force Methoden mittlerweile innerhalb von Minuten geknackt werden.