Scoping in Power Pivot und SSAS Tabular Models
Wenn man in einem SSAS (multidimensionalem) Cube ein Measure definiert, dann wird dieses standardmäßig auf den gesamten Cube angewendet. Es ist jedoch möglich, für Teilbereiche oder sogar einzelne Zellen des Cubes auch spezielle Kalkulationen oder Werte zuzuweisen , die nur dort gelten. Dieses Verhalten erreicht man über sogenannte SCOPE Befehle. Scoping gehört zu den mächtigsten Werkzeugen der Cubes. Umso ärgerlicher ist es, dass es für die ebenfalls populären Schwestertechnologien SSAS Tabular Model sowie Power Pivot kein derartiges Feature gibt.
Was ist Scoping überhaupt? Hier mal ein Beispiel aus dem Demo-Cube von Microsofts Adventure Works DB:
Sie planen Verkaufsquoten für das nächste Jahr auf Quartalsebene und möchten diese gleichmäßig über die Monate verteilen. Das kann man im Cube folgendermaßen erreichen:
-- wird auf alle Monate des Jahres 2002 verteilt. Andere Jahre werden nicht berührt
SCOPE(
[Date].[Fiscal Year].&[2002],
[Date].[Fiscal].[Month].members,
[Measures].[Sales Amount Quota] );
-- Durch das keyword this wird der grade definierte Subcube angesprochen
THIS = [Date].[Fiscal].currentmember.parent / 3;
END SCOPE
Das Ergebnis sieht im Cube so aus:
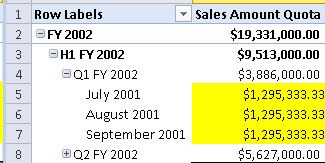
Das Leben kann so einfach sein… aber NICHT für tabellenbasierte Modelle! Wie oben schon angesprochen ist das Feature aufgrund der unterschiedlichen Technologie hier nicht verfügbar. Wir können uns aber zumindest mit einem Trick weiterhelfen. Wie genau das für das genannte Standardbeispiel geht, zeigt z.B. dieser englischsprachige Blogbeitrag.
Nun aber zum eigentlichen Kern des Beitrages. Einer unserer Kunden aus dem Energiesektor kam zuletzt ebenfalls mit einem sehr interessanten Problem zu uns:
Sie wollten eine Tabelle zur Gegenüberstellung von Bestandsveränderung von Artikeln in Ihrem Lager sowie Einkaufskosten und Verkaufserlösen erstellen – Erstmal nicht schwierig und schnell in Power BI gebaut. Das Modell sieht vereinfacht so aus:
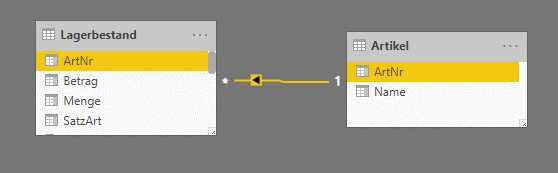
Hier ist „Artikel“ die Dimensionstabelle und „Lagerbestand“ die Faktentabelle, dabei entscheidet das Attribut „Satzart“, ob es sich jeweils um einen Zugang oder Abgang handelt. Der Bericht ist folgender:

Links finden wir Wareneinkäufe pro gehandeltem Artikel sowie den durchschnittlichen Einkaufspreis pro Stück, Rechts die Verkäufe und den Reingewinn, den wir mit allen Verkäufen erwirtschaftet haben.
Wir sehen aber auch sofort eine Anomalie, denn einer der Artikel („Premium Heizöl“) wurde zwar für viel Geld verkauft, ist aber nie eingekauft worden. Hat hier ein Leerverkauf, wie an der Börse stattgefunden? Die Antwort ist nein, denn der Kunde handelt nicht nur, sondern veredelt das eingekaufte Rohöl teilweise auch noch weiter und verkauft es dann für mehr Geld. Unterm Strich ist das dargestellte Gesamtergebnis erstmal richtig, aber wir sehen, dass durch die fehlenden Einkaufspreise die einzelnen Verkaufserlöse addiert nicht die Gesamtsumme ergeben. Wir müssen also die für die Herstellung des Premium Öls eingesetzten Waren aus dem Heizöl herausrechnen und in die obere Zeile schreiben. Wie kann man das in DAX umsetzen?
Einkauf Menge =
CALCULATE (
SUM ( Lagerbestand[Menge] );
Lagerbestand[SatzArt] == 6
)
Weil wir nur Zukäufe berücksichtigen wollen, ändern wir diese wie folgt ab:
SUMX (
// iteriere über alle Dimensionseinträge
VALUES ( Artikel[Name] );
// in bestimmten Fällen nutze andere Kalkulationen, ansonsten nutze std
SWITCH (
Artikel[Name];
„Premium Heizöl“; [Verkauf Menge];
„Heizöl“; // ursprüngliche Formel
CALCULATE (
SUM ( Lagerbestand[Menge] );
Lagerbestand[SatzArt] == 6
)
– CALCULATE (
[Verkauf Menge];
ALL ( Artikel[Name] );
Lagerbestand[SatzArt] == 1;
Lagerbestand[ArtNr] == 61
);
// ursprüngliche Formel
CALCULATE (
SUM ( Lagerbestand[Menge] );
Lagerbestand[SatzArt] == 6
)
)
)
Die neue Formel ist so zu lesen:
Über VALUES(Artikel[Name]) erhalten wir alle Einträge der Artikeldimension, die aktuell sichtbar sind. Es ist wichtig, hier nicht versehentlich die Artikel aus den Fakten zu nutzen, da sonst beim Premium-Öl keine Werte erscheinen werden und es zu weiteren Fehlern kommen kann. Die Funktion SUMX evaluiert nun Zeile über Zeile für jeden der eindeutigen Einträge der VALUES-Funktion die darunterliegende Berechnungsvorschrift. Für das Premium Heizöl ist es die Anzahl der verkauften Einheiten, für das Rohöl die um die Premium Verkäufe geminderten Einkäufe und für alle anderen ändert sich nichts.

Nun müssen wir noch den Einkaufspreis anpassen, da dieser von der Änderung bei den Mengen offensichtlich nichts mitbekommen hat. Hier sehen wir auch sofort die Grenze unseres Workarounds, denn es handelt es sich hier nicht um eine echte Zuweisung wie beim Scope, sondern lediglich um eine Berechnung unseres angepassten Measures zur Laufzeit.
Die Formel für den Preis lautet:
Einkauf Preis =
CALCULATE (
// Den Preis haben wir bereits auf Zeilenebene mit einer
// berechneten Spalte beim Laden in Power Query berechnet,
// um Performance zu sparen. Man rechnet einfach Menge*Betrag=Preis
SUM ( Lagerbestand[Preis] );
Lagerbestand[SatzArt] == 6
)
Hier mussten vorher nur Menge und Einzelpreis zusammengerechnet werden. Das haben wir bereits im Vorfeld beim Datenladen erledigt, um performanter zu sein. Nun erweitern wir diese Formel so, dass sie zur Menge passt.
Einkauf Preis =
VAR DurchschnittlStueckPreisHeizoel =
// Lagerbestand[Preis] / Lagerbestand[Menge] = Durchschnittl. Stückpreis
CALCULATE (
DIVIDE (
CALCULATE (
SUM ( Lagerbestand[Preis] );
Lagerbestand[SatzArt] == 6
);
CALCULATE (
SUM ( Lagerbestand[Menge] );
Lagerbestand[SatzArt] == 6
)
);
ALL ( Artikel[Name] );
Lagerbestand[SatzArt] == 6;
Lagerbestand[ArtNr] == 1
)
RETURN
SUMX (
VALUES ( Artikel[Name] );
SWITCH (
Artikel[Name];
„Premium Heizöl“; CALCULATE (
// Berechne Einkaufsmenge * durchschnittl. Stückpreis von Heizöl Artikel
[EInkauf Menge] * DurchschnittlStueckPreisHeizoel
);
„Heizöl“; // Berechne Einkaufsmenge * durchschnittl. Stückpreis
[Einkauf Menge] * DurchschnittlStueckPreisHeizoel;
// ansonsten ursprüngliche Formel
CALCULATE (
SUM ( Lagerbestand[Preis] );
Lagerbestand[SatzArt] == 6
)
)
)
Wir nutzen hier die bereits angepasste Mengenformel und multiplizieren für die beiden Heizöle die Menge mit dem passenden durchschnittlichen Stückpreis. Hier nutzen wir die Möglichkeit, den Stückpreis in einer Variable vorzuberechnen und zwischenzuspeichern, da wir ihn später öfters benötigen. Für alle anderen Dimensionselemente erhalten wir den Preis durch simple Aggregation. Es ergibt sich das herbeigesehnte Endergebnis.
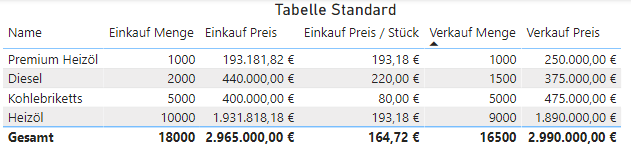
FAZIT
Grundsätzlich ist dieser Workaround sehr mächtig, um die Scope-Funktionalität in Tabularen Modellen zu faken. Jedoch sollte man zwei Dinge immer im Auge behalten. Zuerst einmal handelt es sich hier nicht um eine echte Zuweisung, sondern lediglich um eine dynamische Berechnung. Somit kostet sie bei jeder neuen Evaluation den Prozessor extra Zeit. Außerdem kann man recht schnell den Überblick verlieren, welche dieser Sonderberechnungen man wo in welcher Kennzahl verwendet. Meine Empfehlung ist daher, diese und ähnliche Logiken langfristig bereits in die ETL Schicht des Data Warehouses zu verlagern, um die entsprechenden Zahlen dort bereits vorzuberechnen. Das kostet zwar mehr Zeit, ist aber die auf Dauer nachhaltigere und skalierbarere Lösung.