
„Unscharfe“ Diagramme und Texte in SSRS-Berichten
Bei der interaktiven Darstellung von Diagrammen, z. B. im Report Server oder SharePoint, fallen manchmal verschwommene Texte und Reihen unangenehm auf.
Weiterlesen Bei der interaktiven Darstellung von Diagrammen, z. B. im Report Server oder SharePoint, fallen manchmal verschwommene Texte und Reihen unangenehm auf.
Weiterlesen
Zwei der am häufigsten benutzten Verarbeitungs-Methoden von Dimensionen im Cube sind „ProcessFull“ und „ProcessUpdate“. Gerade letztere Methode wird dann benutzt, wenn der Cube mehrmals am Tag verarbeitet wird, weil z.B. verschiedene Datenquellen zu verschiedenen Zeitpunkte die Daten liefern. Während bei Benutzung von „ProcessFull“ eine Verarbeitung aller mit der Dimension verbundenen Measures notwendig ist, bleiben bei…
Weiterlesen
Getreu dem Motto „Wir bringen Licht ins Dunkel“, sollen Data-Mining-Methoden Wissen sichtbar machen, welches derzeit noch irgendwo in den Untiefen einer Datenbank schlummert und nur darauf wartet entdeckt zu werden. Um uns dabei nicht selber im Dschungel aus Entscheidungsbäumen und linearen Regressionen zu verlaufen oder uns möglicherweise in einem künstlichen neuronalen Netz zu verfangen, atmen…
Weiterlesen
Es kann vorkommen, dass die Berichtsausführung mit einem Fehler aufgrund eines fehlenden Feldes abbricht. Das ist zum Beispiel dann der Fall, wenn in der Abfrage eine Hierarchie verwendet wird, aber nicht immer alle Ebenen der Hierarchie vorhanden sind (nicht balancierte Bäume). Also immer dann, wenn es Blätter auf unterschiedlichen Ebenen gibt. Um diesen Fehler zur…
Weiterlesen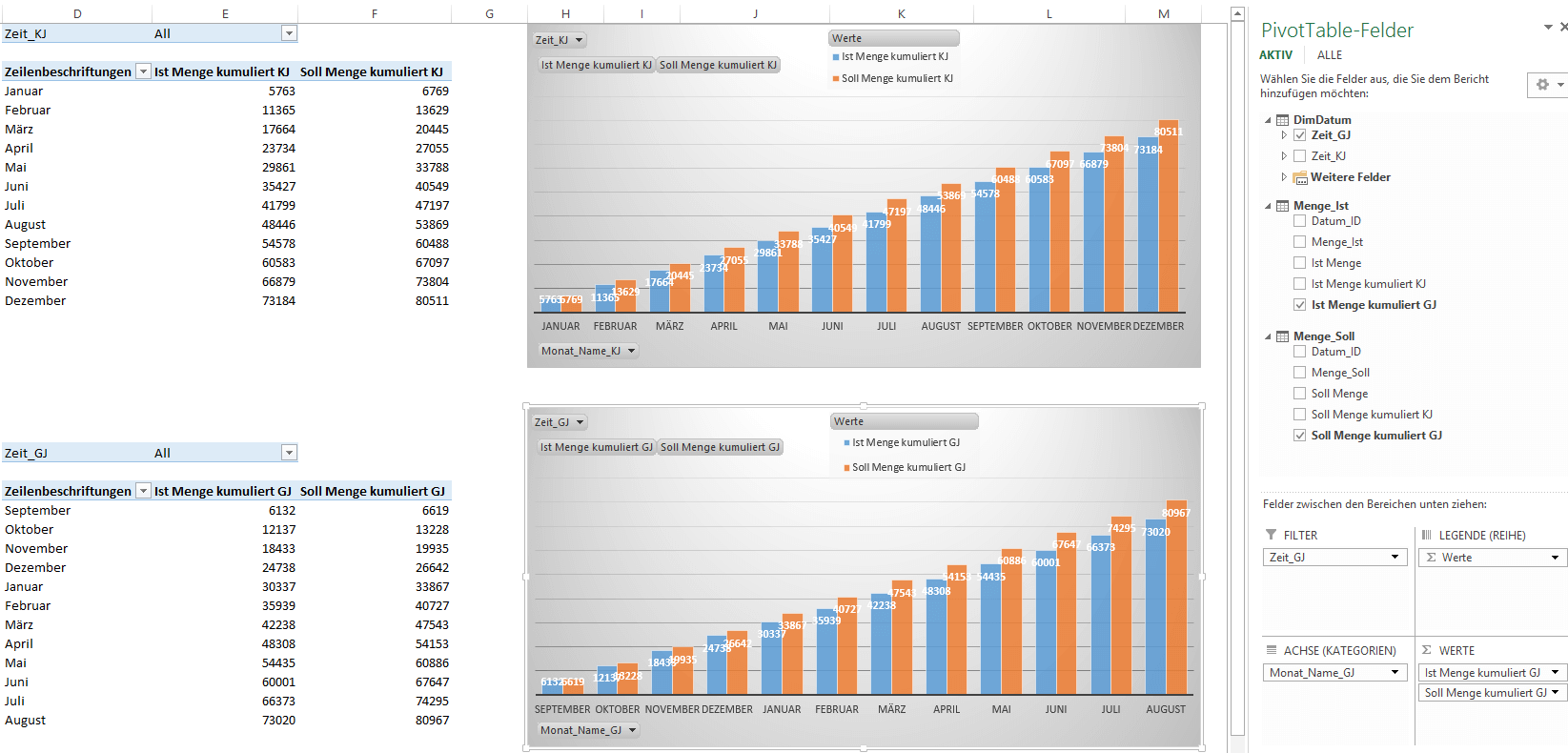
Wenn das Geschäftsjahr vom Kalenderjahr abweicht, kann dieses Schwierigkeiten bei der Erstellung von Diagrammen bereiten.
Weiterlesen Am letzten Wochenende ist mir ein Artikel des Hamburger Abendblatts (29./30. November, Seite 12, „Der Wohlstand lebt im Norden“) in die Hände gefallen. Kurzum, es wurden die durchschnittlichen Pro-Kopf-Einkommen in 2010 der Stadtteile Hamburgs in einer Kartengrafik sehr anschaulich dargestellt. Dennoch ließ es mich etwas stutzen. Ich selbst wohne in Hamburg (Eimsbüttel), ich kenne eine ganze Menge Menschen hier. Besonders…
Weiterlesen